
There is a moment every compliance, legal, and data team knows well. You are about to send a file to outside counsel, a re-insurer, a research partner, or a regulator, and you pause for a second: did we clean this properly? If that question has ever crossed your mind, this guide on redaction vs anonymization vs pseudonymization is for you.
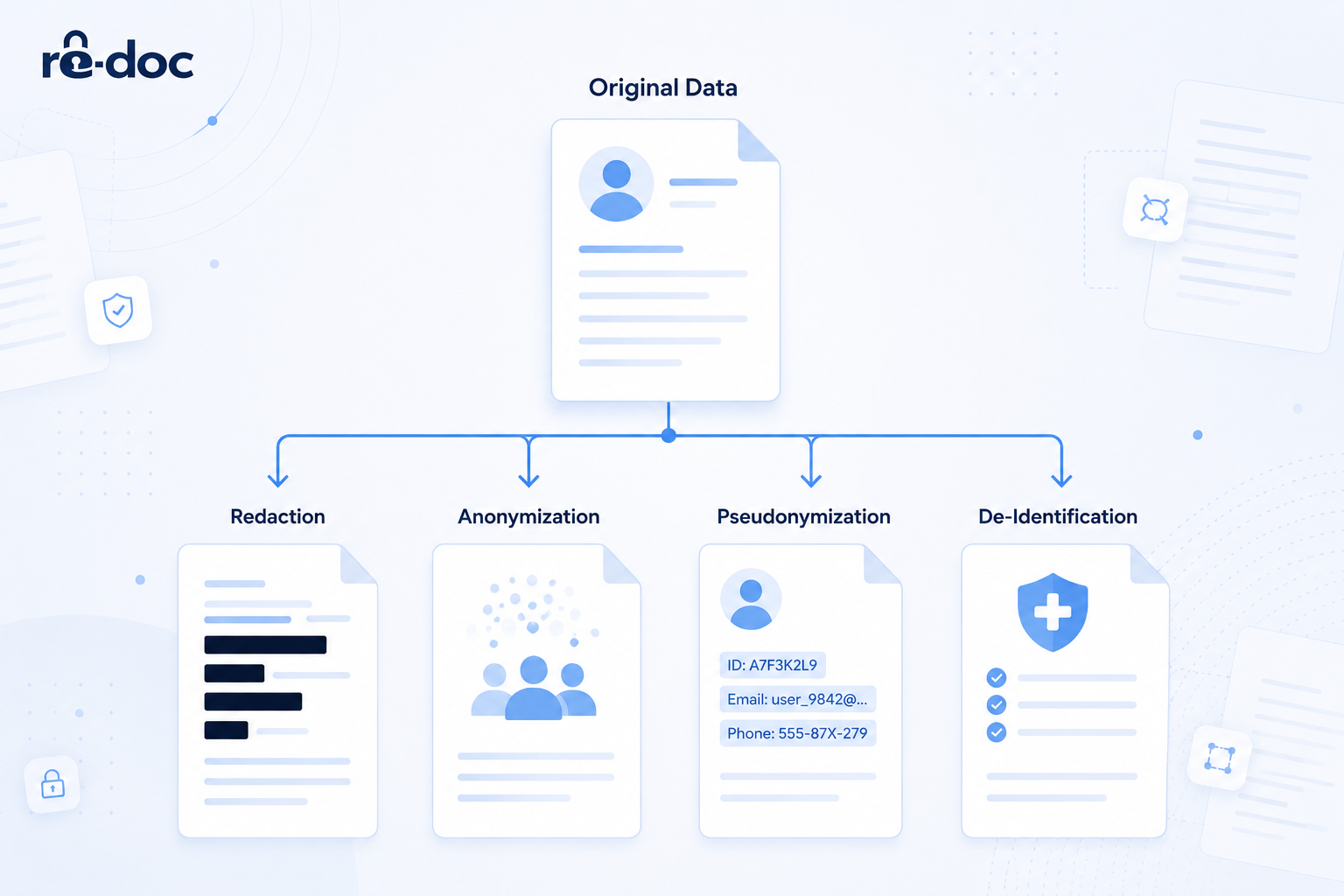
These four terms, redaction, anonymization, pseudonymization, and de-identification, are often used as if they mean the same thing. They do not. Each one solves a different problem, and choosing the wrong one is not just a workflow issue. It can create real regulatory exposure. According to IBM's 2025 Cost of a Data Breach Report, the average breach now costs USD 4.44 million globally and USD 10.22 million in the United States.
By the end of this guide, you will have a simple way to choose the right method for any document. We will also connect that choice to the latest 2025 and 2026 developments, including the EU Court of Justice's landmark EDPS v SRB ruling, the EDPB's new pseudonymisation guidelines, and India's recently notified DPDP Rules, 2025. The goal is simple: make that send-button moment easier to defend.
The one idea that makes the choice obvious
Most explainers define the techniques one by one and then leave you to decide which one is "best." That is where many teams go wrong. These methods are not a ranking where anonymization is better than pseudonymization, and pseudonymization is better than redaction. They sit on a spectrum of reversibility.
At one end is redaction, where the data is gone permanently. At the other end is pseudonymization, where the data can be brought back if someone has the right key. Anonymization sits close to redaction because it is also meant to be irreversible, but it gets there through transformation rather than deletion. The difference between pseudonymized vs anonymized data comes down to one practical question: can the original ever come back?
So ask this question first:
Does anyone, ever, downstream, need to trace this back to a real person?
If the honest answer is no, and nobody ever should, you are looking at redaction or anonymization. If the answer is yes, but only under controlled conditions by an authorized person, you need pseudonymization or de-identification. Keep that question in mind, because every decision below depends on it.
What is data redaction?
Data redaction is the permanent removal of sensitive information from a document. When you redact a field, the underlying data is removed. There is no key, no mapping table, and no safe way to undo it. The recipient gets a file where the sensitive content has been removed from the actual document, not just hidden from view.
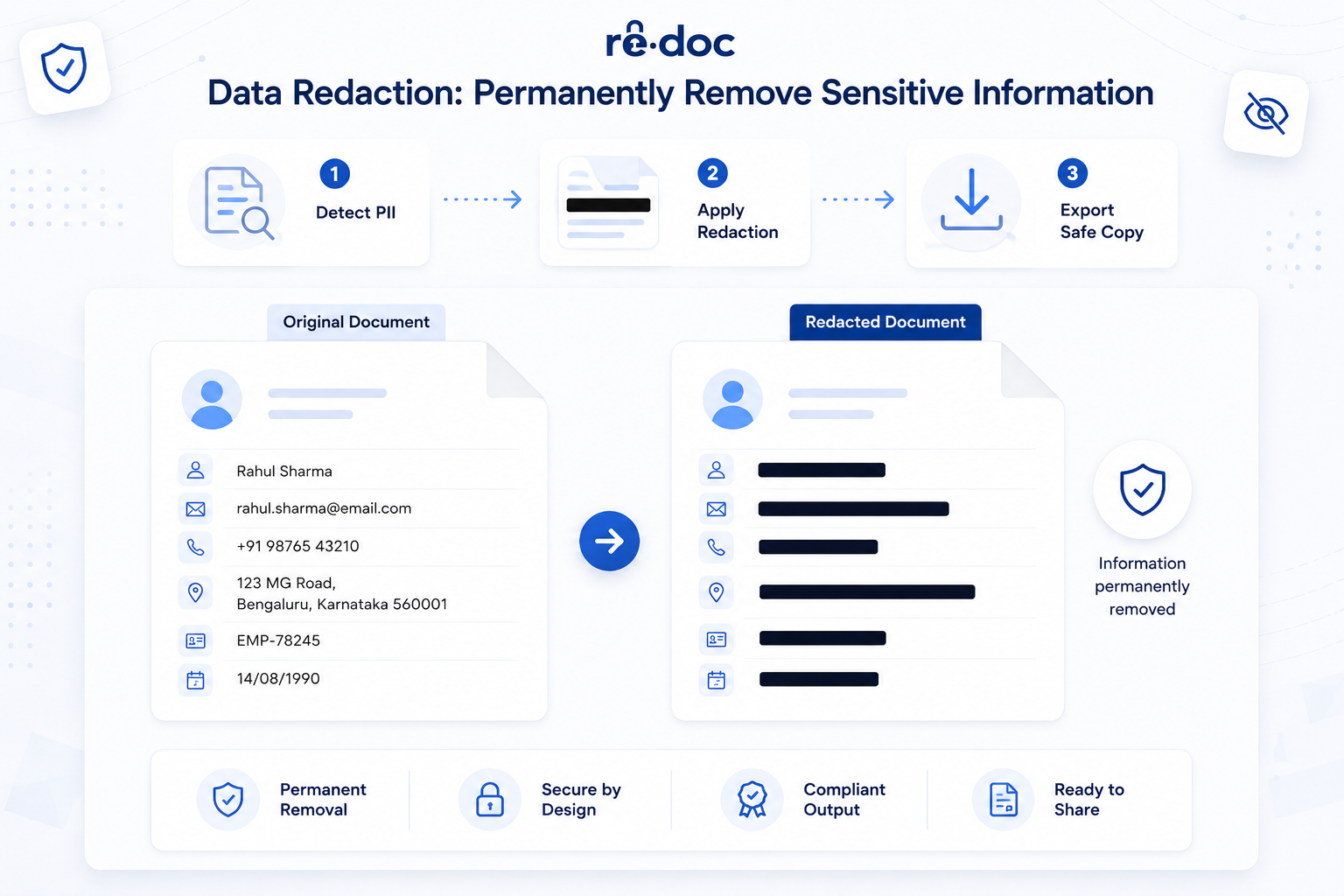
That difference matters. A black box drawn over text in a design tool is only visual masking. The text underneath may still be selectable, searchable, or extractable with copy-paste or a simple script. True document redaction removes the text layer or permanently alters the pixels so there is nothing left to recover. Courts, RTI/FOIA officers, regulators, and opposing counsel expect that level of redaction. For a deeper look at this layout-aware approach, see our guide on preserving utility while proving compliance.
When redaction is the right tool
- You are producing documents in litigation or eDiscovery, and privileged material must never reach the other side.
- You are responding to a Right to Information or Freedom of Information request, where exempt content must be permanently removed.
- You are releasing scanned or image-based PDFs that do not have a clean text layer.
- The document's purpose is release, not reuse.
Where redaction falls short
- The output is less useful for analytics because the information no longer exists.
- Over-redaction, such as removing dates, boilerplate, or useful context "just to be safe," can make the document harder to understand. Courts have also treated aggressive over-redaction as obstruction of disclosure, so it is not harmless caution.
- If you make a mistake, you usually need to return to the source document. There is nothing to "un-redact" in the cleaned version.
What is data anonymization?
Anonymization transforms data so thoroughly that re-identifying a person becomes practically impossible, even if someone combines your data with outside sources. Under the GDPR, genuinely anonymized data is no longer personal data, which means GDPR obligations no longer apply to that data. Recital 26 sets the standard: re-identification must not be possible using "all the means reasonably likely to be used" by anyone.
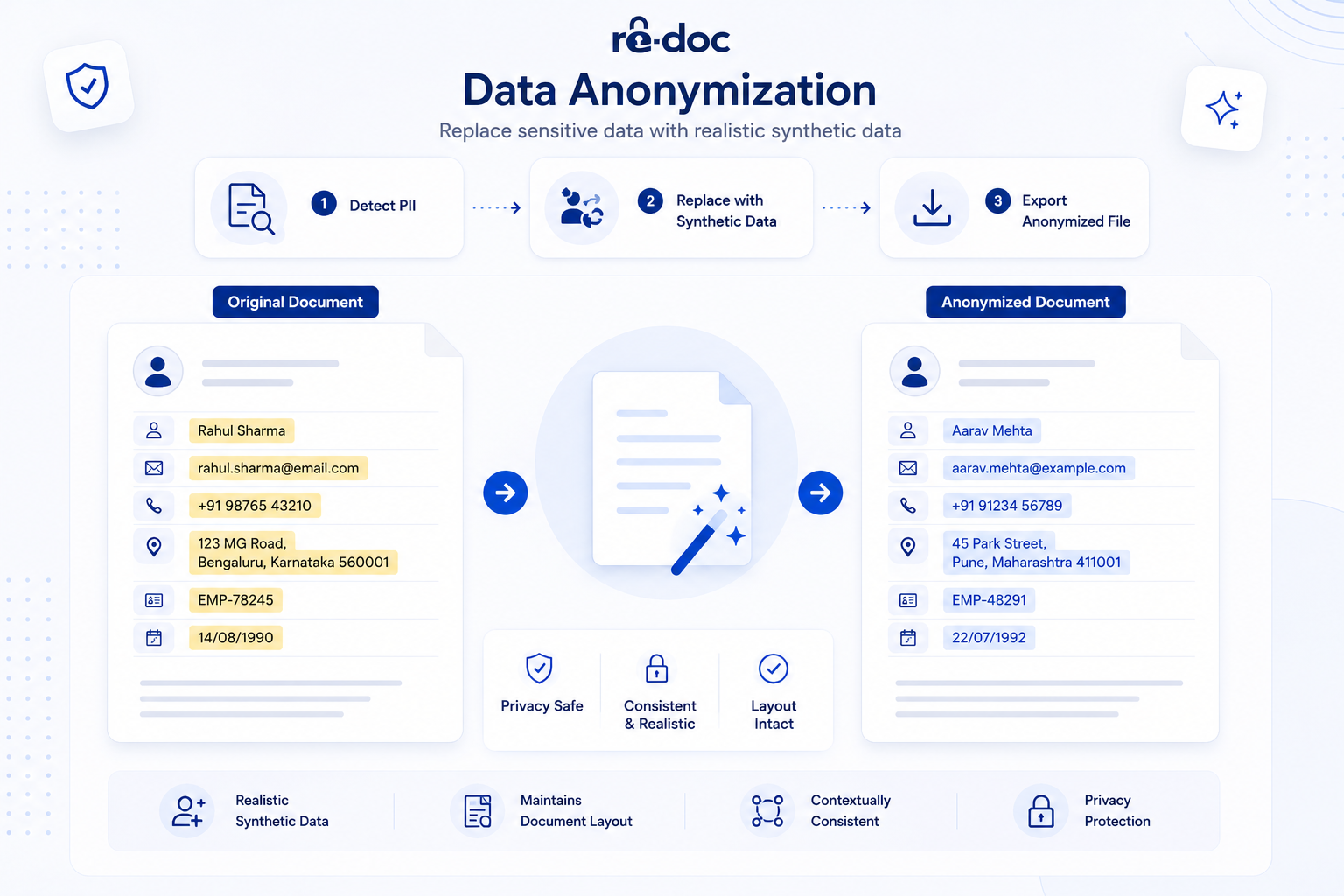
This is where pseudonymization vs anonymization becomes important. Removing names and dates is rarely enough. Regulators have made it clear that quasi-identifiers, such as age, postal code, profession, a rare condition, or a job title in a small town, can still point back to a person even when every direct name has been removed. Anonymization is not just deleting obvious fields. It is a risk assessment across the full document or dataset.
In 2026, that bar is higher because the threat has changed. Research from Staab et al. at ETH Zurich and others shows that large language models can re-identify people from text that older methods may have considered clean. These models can infer location, occupation, and identity from small language clues that a human reviewer might miss. So the question "can anonymized data be re-identified?" has a more uncomfortable answer today: sometimes, yes, more often than teams expect. Gartner projects that by 2027, more than 40% of AI-related breaches will come from improper cross-border use of generative AI. Your anonymization process now needs to account for models that can read between the lines, not just humans with spreadsheets.
For one practical pattern of how layout-preserving synthetic data replacement helps here, our deep-dive on moving from manual redaction to AI-driven synthetic data walks through the workflow end to end.
When anonymization is the right tool
- Publishing datasets for academic research or public-health reporting.
- Training AI/ML models where real PII in the training data could create privacy or leakage risk.
- Archiving historical records that should never again link back to a living person.
- Moving data fully outside GDPR's scope.
Where anonymization falls short
- True irreversibility is hard to achieve without reducing the usefulness of the data.
- It requires a real assessment of quasi-identifiers, not just direct identifiers.
- Once done properly, it cannot be reversed, so longitudinal follow-up is no longer possible.
What is pseudonymization? (And the 2025 ruling that changed it)
The goals of pseudonymization are to reduce risk while keeping data traceable when needed. It replaces identifying information with a stand-in, such as a token, code, or synthetic name, while a separate, secured mapping allows an authorized party to recover the original value. The GDPR, in Article 4(5), treats pseudonymization as a security measure, not as a way to escape compliance. Pseudonymized data is still personal data because re-identification remains possible through the key. A simple way to think about it is this: pseudonymization is like anonymization, but with the key locked in a secure place.
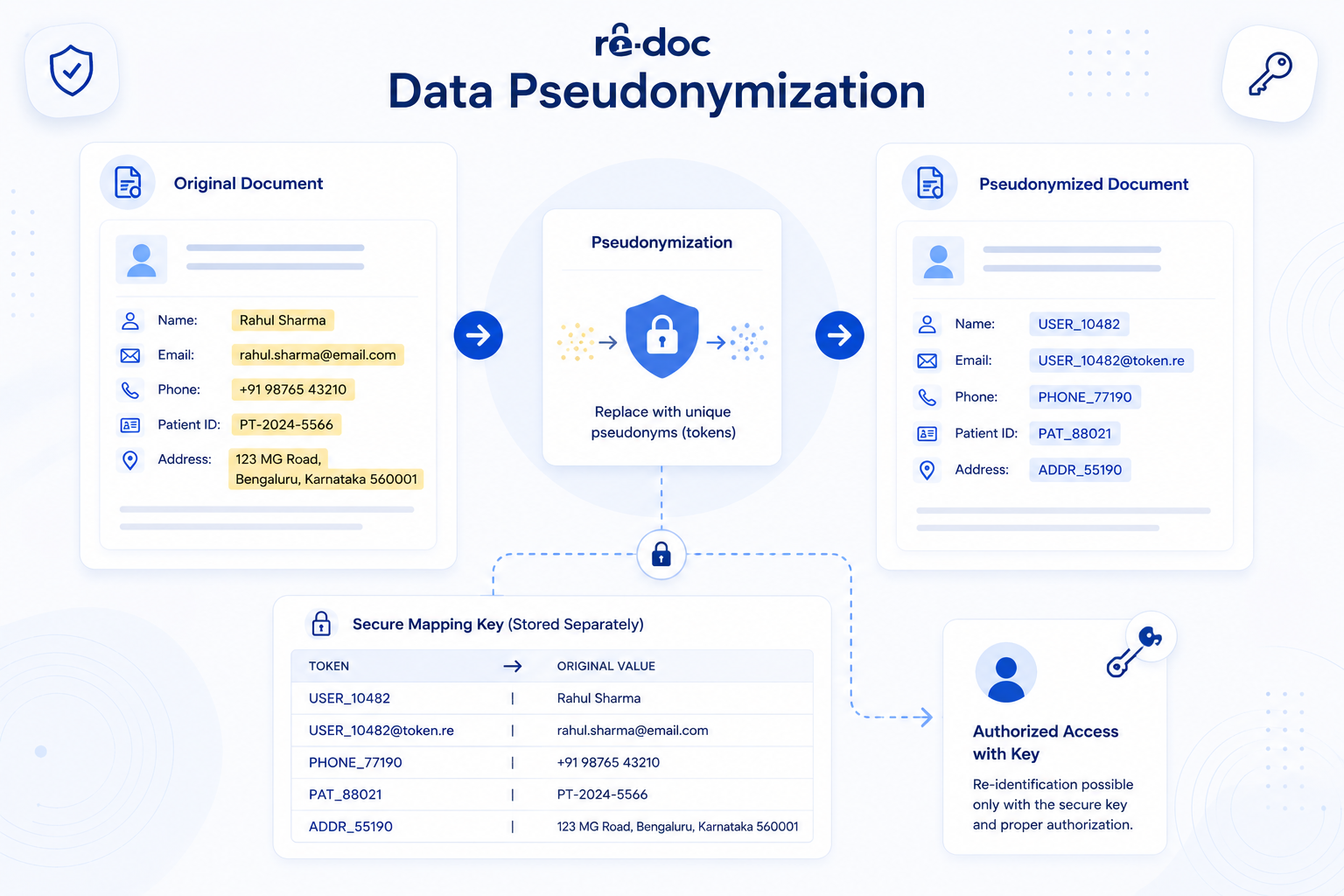
This is common in clinical research. A patient's identity may be hidden from most people working with the data, while a principal investigator can still connect an outcome back to the individual if follow-up is needed.
The EDPS v SRB plot twist
For years, the usual rule was simple: pseudonymized data is always personal data. In 2025, that rule became more nuanced.
On 4 September 2025, the EU Court of Justice issued its decision in EDPS v SRB (Case C-413/23 P). The case came from the resolution of Banco Popular Espanol. The Single Resolution Board collected shareholder comments, pseudonymized them, and shared them with Deloitte for valuation. Deloitte did not hold the key needed to re-identify anyone.
The Court's finding changed how many privacy teams think about pseudonymized data. It held that "personal" is not always an absolute property of data. The same pseudonymized dataset can be personal data for the sender who holds the key, but non-personal data for a recipient who genuinely cannot re-identify anyone using the key or any other reasonable means. In other words, identifiability is relative. It depends on who has the data and what they can realistically do with it.
This creates tension with the EDPB's Guidelines 01/2025 on Pseudonymisation, adopted on 16 January 2025, which leaned more strongly toward treating pseudonymized data as personal data. As of early 2026, the EDPB is still reconciling its guidance with the Court after a December 2025 stakeholder event. The practical takeaway is clear: how you structure a transfer matters. Who holds the key, who receives the data, and what the recipient can realistically do now directly affect your obligations. Architecture is part of compliance.
Where pseudonymization falls short
- The re-identification risk remains as long as the mapping key exists. If the key is compromised, the protection can collapse.
- For the original controller, GDPR obligations still apply.
- It is the wrong method for public releases or FOIA/RTI-style productions, where reversibility is exactly what you must avoid.
De-identification vs anonymization: the HIPAA trap
De-identification gets less attention, but it is central to US healthcare compliance. Under HIPAA, de-identification means either removing or generalizing the 18 specific identifiers in the Safe Harbor method, or using Expert Determination to reduce re-identification risk to a "very small" level.
Here is the trap for cross-border teams: in the de-identification vs anonymization comparison, what HIPAA calls de-identification often looks closer to GDPR pseudonymization than GDPR anonymization. A document can qualify as de-identified under HIPAA Safe Harbor and still be treated as personal data under GDPR if some residual re-identification risk remains. So:
- HIPAA de-identification is roughly equivalent to GDPR pseudonymization in privacy strength.
- GDPR anonymization is a stricter standard, with essentially zero re-identification risk.
- If both regimes apply, the stricter standard usually wins.
Redaction vs anonymization vs pseudonymization: the differences at a glance

| Redaction | Anonymization | Pseudonymization | De-identification (HIPAA) | |
|---|---|---|---|---|
| What happens to the data | Permanently destroyed | Transformed beyond recovery | Replaced with a reversible stand-in | Identifiers removed or generalized |
| Reversible? | No | No | Yes, with the key | Depends on method |
| Still personal data under GDPR? | No | No | Yes | Likely yes |
| Still PHI under HIPAA? | No | No | Depends | No, if done properly |
| Fit for public release? | Yes | Yes | No | Conditional |
| Data usable for analytics? | Limited | Aggregate only | Yes | Yes |
| Primary use case | Legal, RTI/FOIA, court docs | Research, AI training | Healthcare, internal research | US healthcare compliance |
The 3-question test
Run your workflow through these three questions. In most cases, the right method becomes obvious.
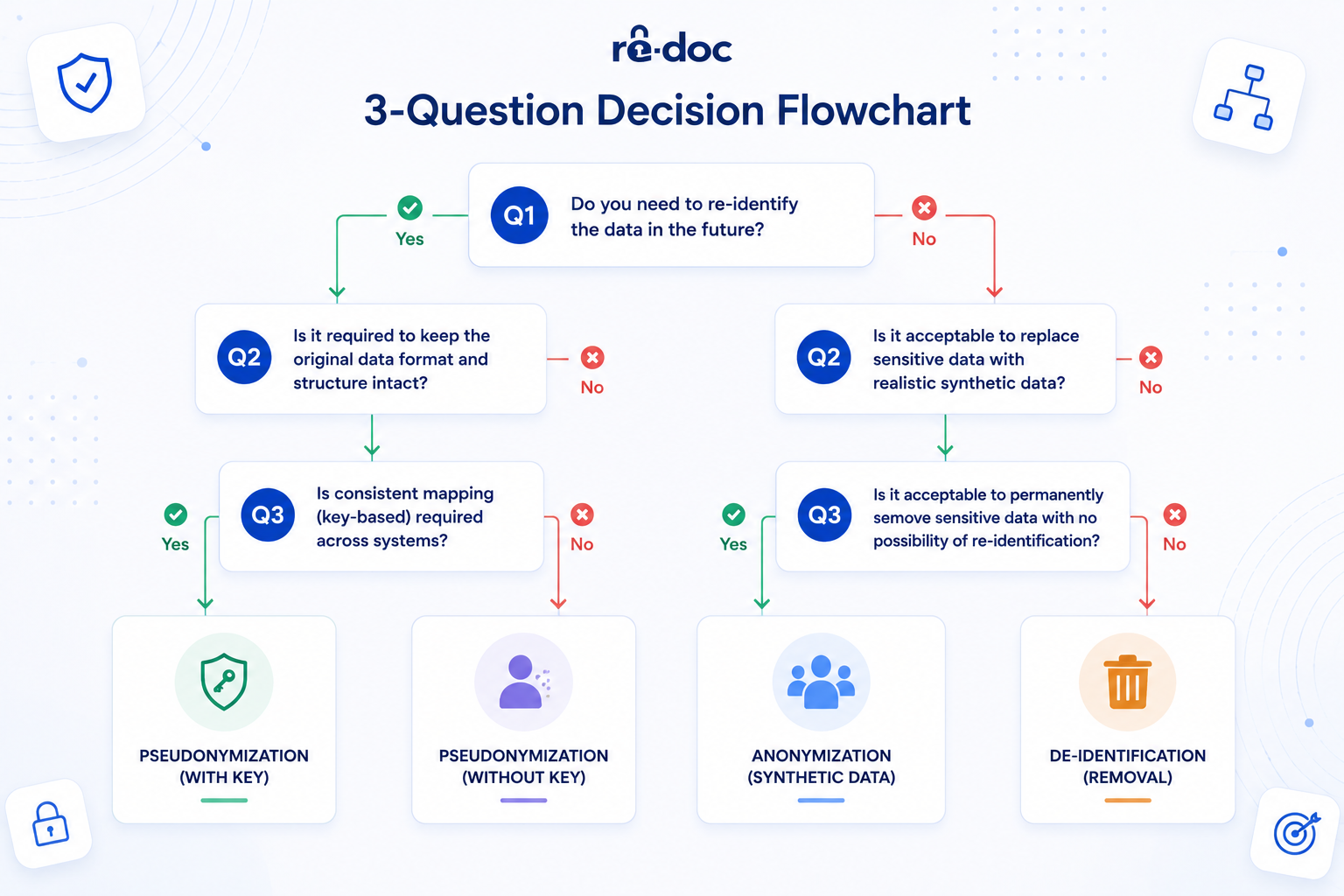
-
Does anyone downstream ever need to trace this back to a person? Yes means pseudonymization or de-identification. No, and nobody ever should, means anonymization, or redaction if the goal is document release.
-
Who receives this document? External parties, such as opposing counsel, regulators, partners, or the public, usually require a stricter standard. Internal teams, such as developers using test data or clinicians planning a protocol, may be able to work with pseudonymized data if the key is properly controlled. After EDPS v SRB, the recipient's ability to re-identify someone can change the legal status of the data.
-
Which regulation governs this data? If GDPR applies and you want the data to fall out of scope, you need true anonymization. If HIPAA applies and you are sharing PHI for research without authorization, use Safe Harbor or Expert Determination. If the DPDP Act applies because you process data of people in India, the timeline now matters, because compliance is already moving into implementation.
What this means in India right now (DPDP Act 2025)
If you process the personal data of people in India, 2026 is the year this became practical rather than theoretical. On 13 November 2025, MeitY notified the Digital Personal Data Protection Rules, 2025, which operationalize the DPDP Act, 2023, two years after the Act was passed. The framework will roll out in phases, with full compliance expected by 13 May 2027.
For document workflows specifically:
- The DPDP Act applies extra-territorially. Like GDPR, it can apply to foreign companies that process the data of people in India while offering goods or services to them. A vendor outside India handling Indian customer files can still be in scope.
- The Rules tighten requirements around consent, breach notification, retention limits, and the duties of Significant Data Fiduciaries.
- The transition period should not be treated as spare time. It is the runway to fix document handling and vendor sharing before the Data Protection Board of India begins enforcement.
For Indian fintech, insurance, legaltech, and healthcare teams, the files shared with offshore processors, partners, and service providers are exactly the kind of documents this regime will scrutinize. A reliable redaction and anonymization layer is now part of the compliance plan, not a nice-to-have.
Redaction and anonymization in real document workflows
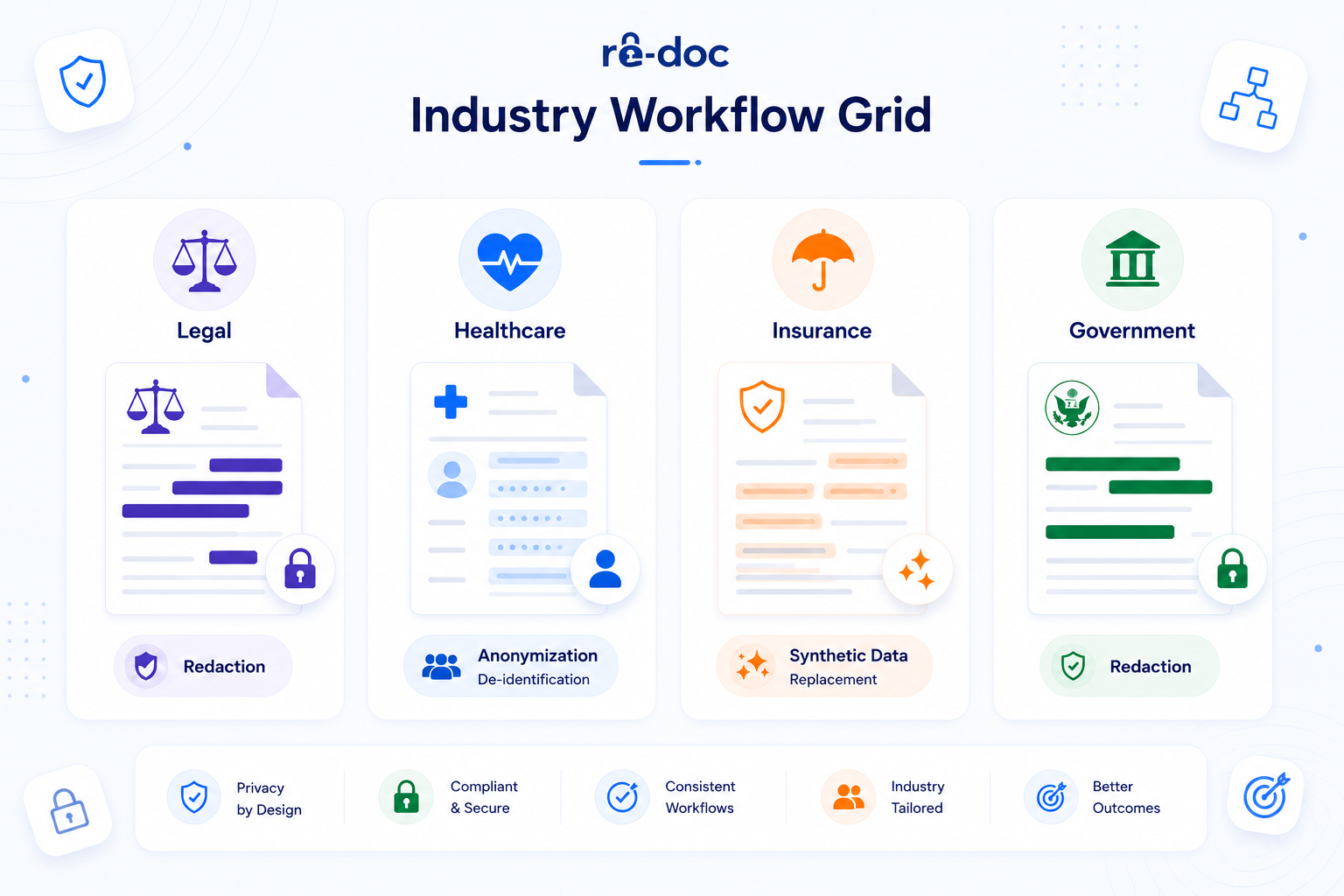
Legal and eDiscovery
Privileged material must be redacted permanently. Pseudonymization is not suitable here because it implies reversibility, and courts expect blacked-out information to be gone. At discovery scale, where teams handle thousands of pages, manual redaction quickly becomes the bottleneck. Automated, layout-preserving redaction that can survive forensic review is the standard teams should aim for. See how this fits a legal review pipeline on our legal solutions page.
Healthcare
Healthcare usually needs all three methods, depending on the workflow. Records shared outside a covered entity for research may need HIPAA de-identification. Clinical trials often use pseudonymization so investigators can connect outcomes back to patients when needed. Research-grade datasets for AI training need full anonymization, especially if any EU patients are involved and the GDPR standard applies. The challenge is that discharge summaries, clinical notes, and referral letters are often messy. They include free text, handwriting, scanned pages, and mixed formats, so OCR, scanned-file handling, and layout preservation matter. The healthcare solutions page covers this in more detail.
Insurance and financial services
Claims files, attached medical records, and KYC forms often move between third-party processors, offshore teams, and re-insurers. Redaction works when the release must be permanent. Synthetic data replacement, where real identifiers are replaced with realistic but fictional equivalents, works when the document still needs to read naturally and remain useful for the receiving team. Our insurance solutions page lays out the most common claims-handling and re-insurance patterns.
Government and RTI/FOIA
There is little room for ambiguity here. Exempt information must be permanently removed before release. With request backlogs growing and manual review often becoming the chokepoint, automated redaction is not only a productivity improvement. It is part of the compliance process. The government solutions page walks through RTI and FOIA workflows.
Where data masking fits in
The data anonymization vs data masking question confuses teams because the two can look similar from the outside. Data masking hides or replaces data inside databases and test systems. For example, it may replace real SSNs or account numbers with structurally valid fake values so developers can test systems without seeing real customer data. In privacy terms, masking often behaves more like pseudonymization. The key difference in data masking vs data anonymization is the layer where it happens: masking is a system-level technique, while redaction and document anonymization happen at the file level, on the document you are preparing to share.
Five mistakes that quietly create liability
- Treating a black box as anonymization. If the original unredacted file still exists in your system, you have not truly anonymized the information. Anyone with both versions may be able to compare them.
- Using cosmetic redaction on PDFs. A rectangle placed over a text layer does not delete the text. It may still be searchable or extractable.
- Assuming HIPAA satisfies GDPR. It does not always. Treat HIPAA-de-identified data as GDPR-pseudonymized unless you have confirmed that the stricter GDPR anonymization standard is met.
- Over-redacting to feel safe. Removing non-sensitive context can make a document incomplete or legally insufficient. Courts have treated this as obstruction in some cases.
- Trusting old anonymization against new AI. Methods that worked against a human with a spreadsheet may not work against models that infer identity from language patterns. Validate anonymization against the 2026 threat model.
What to look for in a redaction tool
The method is only as reliable as the tool used to apply it. When evaluating data redaction tools, these five criteria separate compliance-ready software from tools that create risk.
For document redaction workflows, this usually means reliable OCR, named entity recognition, PII and PHI detection, layout preservation, auditability, and deployment options that match your data residency requirements.
- Detection accuracy across messy formats: names, IDs, account numbers, addresses, and medical record numbers should be detected reliably across scanned and native files. A false negative can become a compliance failure, while too many false positives can make the document unusable.
- Format coverage: scanned PDFs, native PDFs, Word documents, and images all matter. One-format tools leave gaps where real workflows happen.
- Layout preservation: a cleaned document that loses its tables, spacing, and structure is hard to use, even if it is technically compliant.
- Deployment flexibility: data residency, strict client requirements, and air-gapped environments often make on-premise and local options essential.
- Human-in-the-loop review: automated detection should handle the first pass, but reviewers still need a clear way to confirm, adjust, and approve the output.
The bottom line
Redaction, anonymization, pseudonymization, and de-identification are not better or worse versions of the same thing. They are different methods for different jobs, and the most important difference is reversibility. The main question is simple: does anyone downstream ever need to trace this back to a person?
That is the simplest way to think about redaction vs anonymization vs pseudonymization: redaction removes, anonymization transforms irreversibly, and pseudonymization replaces while preserving a controlled path back to the original identity.
- Redact when the output is permanent, leaves your organization, and should never be recovered.
- Anonymize when you need data for research or AI and must meet the highest privacy standard, especially now that AI has raised the re-identification risk.
- Pseudonymize when authorized re-identification must remain possible under controlled conditions. Structure the transfer carefully, because after EDPS v SRB, the architecture can affect classification.
- De-identify for US healthcare under HIPAA, while remembering that it is not the same as GDPR anonymization.
When you get the document type, recipient, regulation, and reversibility right, that cursor-over-send moment becomes a decision you can explain and defend.
Ready to put this into practice?
Re-Doc is a document anonymization and redaction platform built for exactly these decisions. It supports permanent black-box redaction for scanned documents and synthetic data replacement for native PDFs and Word files. The result is a clean document that stays readable and keeps its layout, so the file remains useful after sensitive data is removed or replaced.
Whether you are a legal team preparing discovery, a healthcare administrator handling compliant releases, an insurer sharing claims across borders, or an Indian business preparing for the DPDP 2027 deadline, Re-Doc fits into your existing document workflow. It supports cloud, desktop, and on-premise deployment for teams with strict data-residency or security needs.
Frequently asked questions
What is the difference between redaction and anonymization?
Redaction permanently removes specific information from a document. Anonymization transforms the document or dataset so individuals cannot be identified. Both are meant to prevent tracing data back to a person, but anonymization works at a broader level and requires a stronger standard of irreversibility.
Is pseudonymization the same as anonymization under GDPR?
No. Pseudonymized data is still personal data because re-identification is possible through the mapping key. The 2025 EDPS v SRB ruling clarified that the same pseudonymized data may be non-personal for a recipient who genuinely cannot re-identify anyone, so the answer depends on who holds the data and what they can realistically do with it.
Is pseudonymized data still personal data?
For the party that holds the key, yes. After EDPS v SRB, a recipient who cannot reasonably re-identify anyone may hold data that counts, for them, as non-personal. This makes the test relative and context-dependent rather than absolute.
What are the goals of pseudonymization?
The goals are to reduce re-identification risk and improve security while keeping data traceable for authorized purposes, such as clinical follow-up or internal analytics. GDPR treats pseudonymization as a security measure, not as a way to remove all compliance obligations.
What is the difference between de-identification and anonymization?
HIPAA de-identification, through Safe Harbor's 18 identifiers or Expert Determination, is often closer in strength to GDPR pseudonymization. GDPR anonymization is stricter and requires essentially zero re-identification risk. That means HIPAA-de-identified data may still be personal data under GDPR.
What is the difference between data anonymization and data masking?
Data masking is a system-level technique that disguises data inside databases and test environments. Document anonymization works at the file level on a finished document. In privacy terms, masking often behaves more like pseudonymization.
What is data redaction in documents?
Document redaction is the permanent removal or blacking out of sensitive information from files such as PDFs, Word documents, and scanned images. True redaction removes the underlying text or pixels, not just the visible layer, while preserving the layout so the output stays usable.
Can anonymized data be re-identified?
Yes, if quasi-identifiers remain or if modern AI tools can infer identity from the content. Research on large language models has shown that text older methods considered clean may still contain clues. That is why anonymization should be validated against current AI capabilities.
What are the best data redaction tools for compliance?
The best tools combine accurate PII detection, support for scanned and native formats, layout preservation, and a human-in-the-loop review step. Re-Doc, for example, offers permanent black-box redaction and synthetic data replacement with cloud, desktop, and on-premise deployment.
Is data redaction the same as data masking?
No. Data redaction permanently removes sensitive information from a document, while data masking usually hides or replaces values in databases, test environments, or application screens. Redaction is better for final document release; masking is better for controlled internal systems.
When should I use anonymization instead of pseudonymization?
Use anonymization when nobody should be able to trace the data back to a real person, even internally. Use pseudonymization when authorized re-identification is still required, such as clinical follow-up, internal analytics, or controlled research workflows.
Redact, replace, or do both in a single pass to protect sensitive data
About Re-Doc: Re-Doc is an automated document redaction and anonymization platform that turns sensitive documents into layout-perfect, shareable assets. It supports scanned PDFs, native PDFs, and Word documents with permanent redaction and synthetic data replacement, serving legal, healthcare, insurance, and government teams with cloud, desktop, and on-premise deployment.